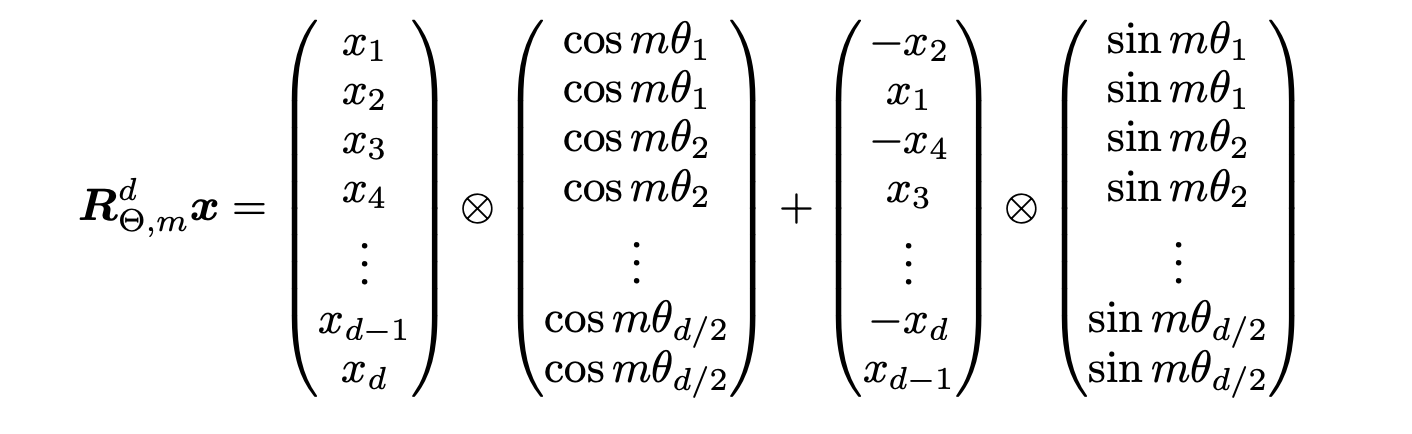Abstract
LLaMA大模型是Meta AI发布的一个开源的,基于完全公开的数据集进行训练的大语言模型,具有能够和GPT等商业大模型竞争的能力。由于该模型面向学术界开源,因此也产生了很多基于LLaMA的工作。本文则是对其背后的论文 LLaMA: Open and Efficient Foundation Language Models 所做的阅读笔记。
Larger Model or Larger Data
Model
当计算资源一定的时候,我们应该扩大模型的参数量,还是应该扩大数据的规模?Hoffmann等人在2022年的工作表明,当计算资源一定的时候,通过在较小的模型上训练更多的数据,会产生最佳的效果。该工作给出的建议是在一个200B的token上训练一个10B大小的模型。然而,这一结论主要是针对训练时而言。如果考虑推理的成本,那么更小的模型虽然需要花费更长的时间,更多的成本去达到较大模型的性能,但长久来看其成本要比维护一个较大的模型更少。因此,工作者们选择在相比其他商业模型更小的模型上训练更长的时间,并取得了有竞争力的结果。例如,参数量为13B的LLaMA模型在大多数benchmark上都取得了超越参数量为135B的GPT-3大模型的表现。
Data
Dataset
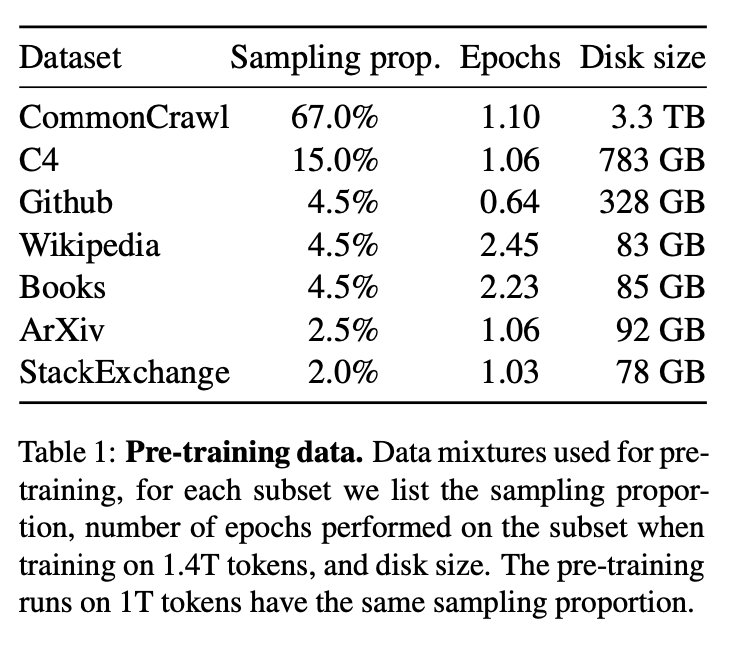
LLaMA采用了以下数据进行训练
Tokenizer
LLaMA的tokenizer采用了BPE算法,值得注意的是,LLaMA将所有的数字都拆开,并将每个数字视为一个单独的token。
BPE算法是一种subword分词方法,其算法流程如下:
- 在每个单词末尾添加
</w>,标记为单词结尾,并统计其出现次数,作为初始化的词表 - 将每个单词按字符分割
- 统计每个字符对的出现次数,选择出现频率最大的字符对融合成新的token,加入词表
- 重复上述操作,直至词表达到设置大小,或达到最大迭代次数
Modify the Transformer
LLaMa模型依然采用了Transformer架构(Decoder only),但也做出了几处修改,以提高模型性能:
- Pre-normalization
- SwiGLU activation function
- Rotary Embeddings
Pre-normalization
LLaMA受到GPT3启发,选择对transformer的输入进行标准化,而非原transformer论文中对输出进行标准化,以提高模型训练的稳定性,同时,LLaMA采用了RMSNorm标准化方式。
Pre-norm VS Post-norm
Ruibin Xiong等人[2]的工作中提到,尽管Post-Norm的训练方式得到的模型具有良好的表现,但其通常在训练阶段不够稳定,一般来说需要设置learning rate的warm up阶段,也即需要在训练开始时从一个特别小的学习率递增到正常大小的学习率。这样的一个warm-up阶段会导致优化速度的减慢,同时,模型的表现也对warm-up阶段的超参数敏感。
该研究表明,如果像传统的transformer一样,将layer normalization层放置在残差块之间,即Post-norm,会导致靠近输出层的参数得到的梯度较大,从而导致了训练的不稳定性。而如果将layer normalization层放置在残差块内部,即Pre-norm,梯度大小则表现良好。进一步的实验表明,如果采用Pre-norm的方式,warm-up阶段则可以被安全的去除,从而减少了超参数的数量,提升了训练的稳定性。
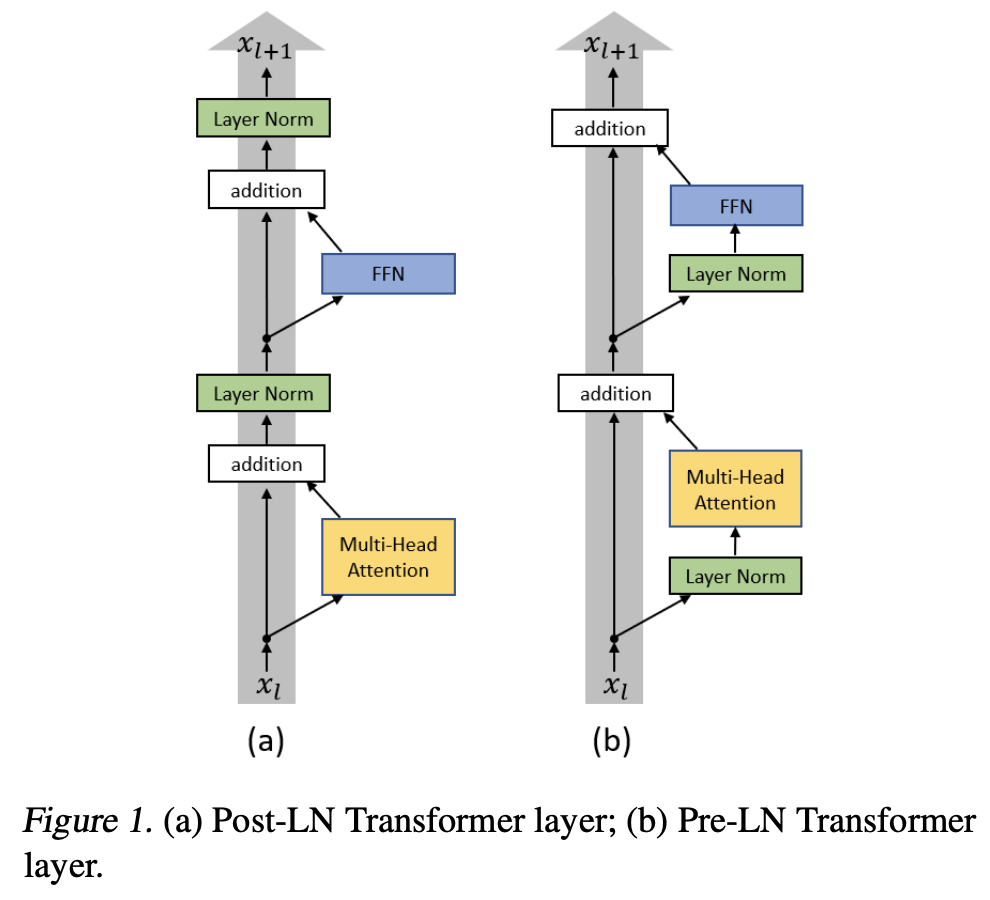
RMS norm
RMS norm计算公式如下:
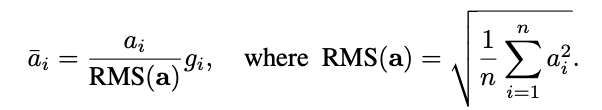
其中
SwiGLU avtivation function
LLaMA用SwiGLU函数替代了原有了ReLU函数以提高表现
原始的ReLU函数我们已经很熟悉了,其后有工作提出了GeLU算法
1 | def gelu(x): |
GeLU其实可以视为平滑版的ReLU函数,并且处处可导
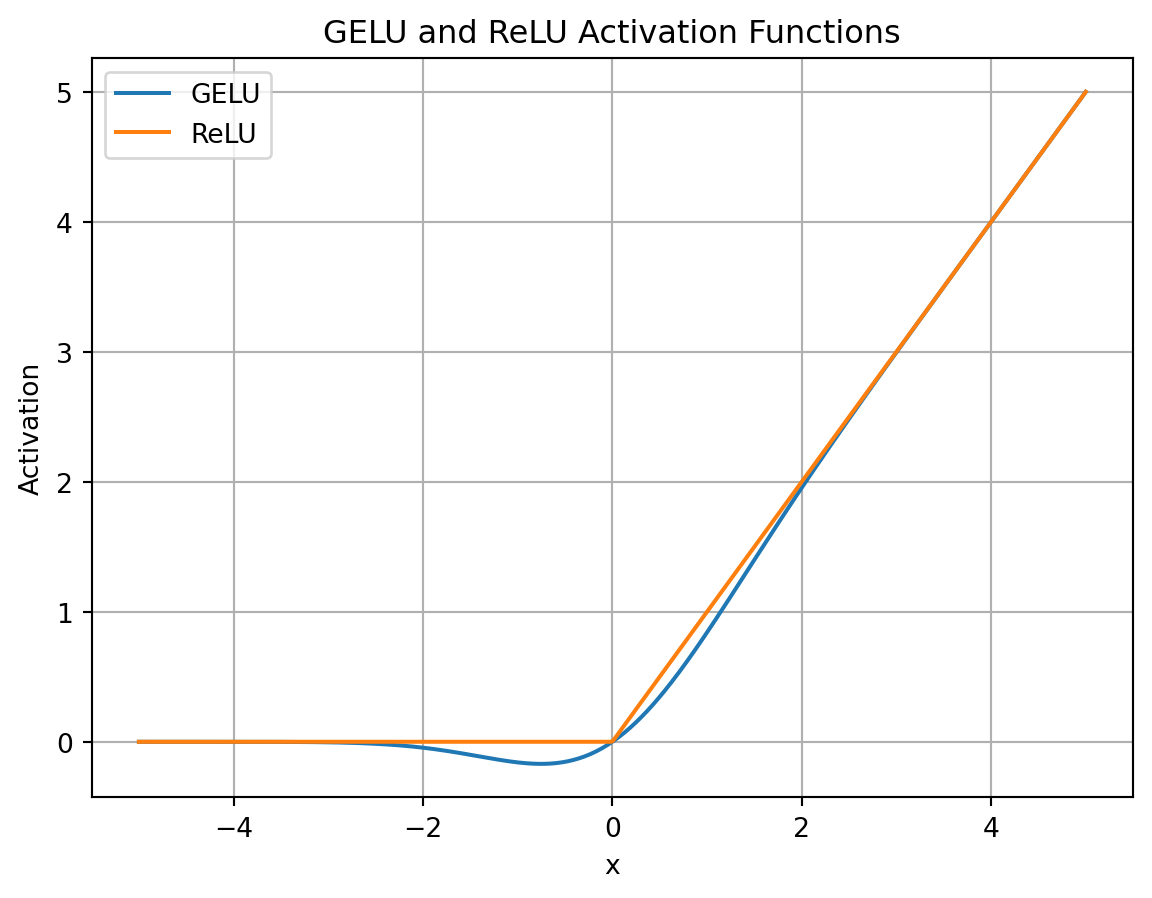
其后又出现了Swish函数
1 | def swish(x, beta): |
该函数同样处处可微,同时引入了beta参数来控制曲线的形状
现在可以引入各种GLU,即门控线性单元,门控线性单元并不是一种激活函数,而是一个神经网络层,通常情况下,一个GLU可以表示为
Rotary embeddings
LLaMA用旋转位置编码取代了绝对位置编码。
对于token的位置编码,可以表示为
与注意力机制相结合,以查询Q的计算为例,首先需要将x进行一个线性的投影,即
扩展到d维的向量表示,由于内积具有线性叠加性,因此任意偶数维度的内积运算都可以视为若干个二维的内积运算的拼接,其旋转矩阵也可以写为:
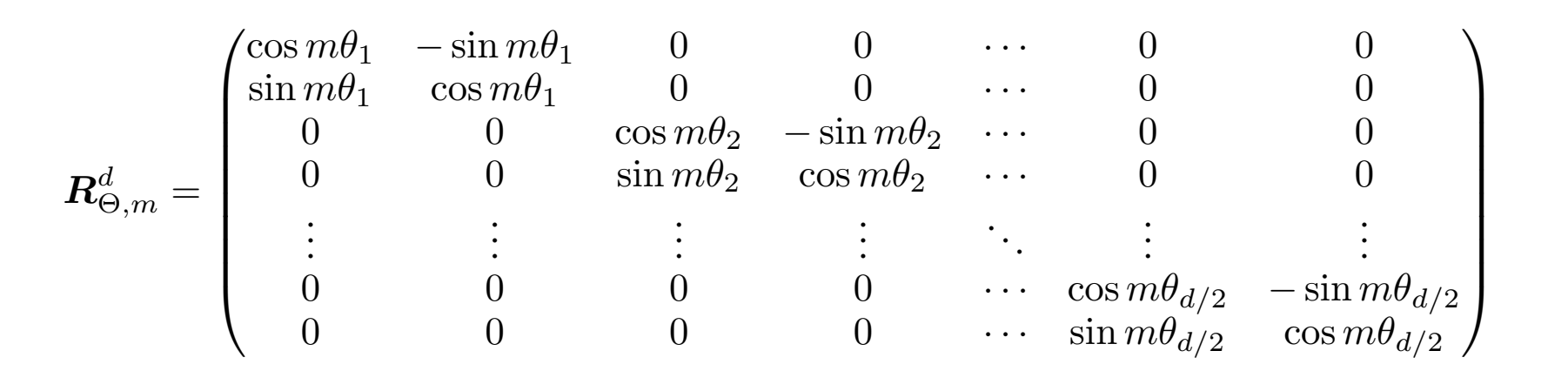
其中,
由于上述旋转矩阵的稀疏性,可以将旋转矩阵的计算改写为逐元素乘法的形式