章水和贡水交汇的地方,叫做赣
南昌
CAD/CG 2024
一周之前wjj跟我说要不要参加一下CAD/CG的挑战赛,我很快的就答应了。一是为了那个一等奖的奖金;二是为了能去开个学术会议看看流程;三则是正好今年的 CAD/CG会议开在南昌,可以去江西转转。
于是花了一周的时间把pipeline糊好,靠着还可以的运行结果和讲的不错的故事去了南昌参加线下的决赛。
章水和贡水交汇的地方,叫做赣
一周之前wjj跟我说要不要参加一下CAD/CG的挑战赛,我很快的就答应了。一是为了那个一等奖的奖金;二是为了能去开个学术会议看看流程;三则是正好今年的 CAD/CG会议开在南昌,可以去江西转转。
于是花了一周的时间把pipeline糊好,靠着还可以的运行结果和讲的不错的故事去了南昌参加线下的决赛。
扩散模型已经成为了当下最火的生成模型,不仅在图像生成领域,许多其他模态的生成任务也开始广泛的应用扩散模型。而让该模型真正得到广泛应用的工作即为2020年所发表的论文《Denoising Diffusion Probablistic Models》
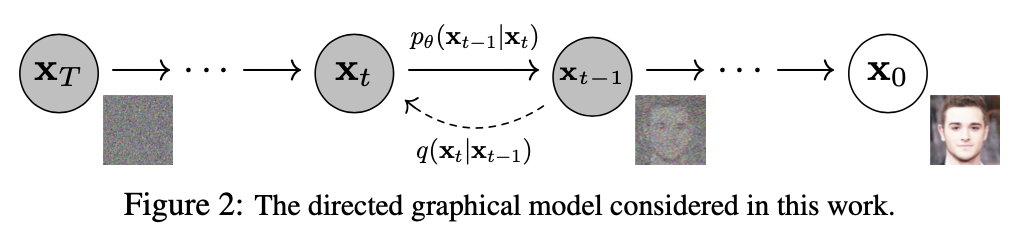
如上图,Diffusion
Model的核心便在于前向和逆向的两个过程。一般而言,Diffusion
Models的形式为
LLaMA大模型是Meta AI发布的一个开源的,基于完全公开的数据集进行训练的大语言模型,具有能够和GPT等商业大模型竞争的能力。由于该模型面向学术界开源,因此也产生了很多基于LLaMA的工作。本文则是对其背后的论文 LLaMA: Open and Efficient Foundation Language Models 所做的阅读笔记。
当计算资源一定的时候,我们应该扩大模型的参数量,还是应该扩大数据的规模?Hoffmann等人在2022年的工作表明,当计算资源一定的时候,通过在较小的模型上训练更多的数据,会产生最佳的效果。该工作给出的建议是在一个200B的token上训练一个10B大小的模型。然而,这一结论主要是针对训练时而言。如果考虑推理的成本,那么更小的模型虽然需要花费更长的时间,更多的成本去达到较大模型的性能,但长久来看其成本要比维护一个较大的模型更少。因此,工作者们选择在相比其他商业模型更小的模型上训练更长的时间,并取得了有竞争力的结果。例如,参数量为13B的LLaMA模型在大多数benchmark上都取得了超越参数量为135B的GPT-3大模型的表现。
我们知道,对于计算机来说,图像、视频、文字等信号都是用离散的数字去表示的。以图片为例,对于神经网络而言,当然可以直接把像素直接作为输入,并基于这些像素去做各种的下游任务,例如图像分类、文生图片等。那么,encoder的意义到底是什么?
以我个人的观点来看,encoder的作用实际上是去除数据中的噪声,压缩数据的大小,提取数据之间的共性,其最终目的是获得一个更高效的、更适合下游任务的表示来替代原始的数据。例如,假设我们现在正在想知道一个图片所表示的文本(CLIP),数据集中有一张猫站在草地上的图片和一张猫站在地板上的图片,而对应的文本描述都是 a photo of a cat,我们显然希望能够将这两张图片用类似的特征去表示[1],这时我们就会使用encoder将原始的差异很大图片编码成两个类似的特征,并且,用来表示这张图所需的数字要小得多。例如一张512*512*3的图片,可能最终只需要2048维,也就是2048个数字去完全表示。
Auto Encoder,即自编码器,其是用在没有标签的数据集上的,也就是说是一种无监督的算法。相对于上文中提到的CLIP编码器,这种编码器没有任何的监督,其目的在于去除噪声、压缩数据,即用更少的数据去保留原数据更多的信息。它的作用可以类比于一个压缩软件,可以把数据压缩成另一种格式(类比.zip文件),并且还能再还原出原数据。